
KAPA Universal Adapter and KAPA UDI Primer Mixes work together to provide high library conversion efficiency and improve data quality and analysis. Together, they have been validated for DNA library preparation (with KAPA HyperPrep and KAPA HyperPlus Kits), hybridization-based target enrichment (with the KAPA HyperCap Workflow v3), and RNA library preparation (with KAPA RNA HyperPrep Kits).
Truncated Adapters
For Research Use Only. Not for use in diagnostic procedures.

Deliver high library conversion efficiency
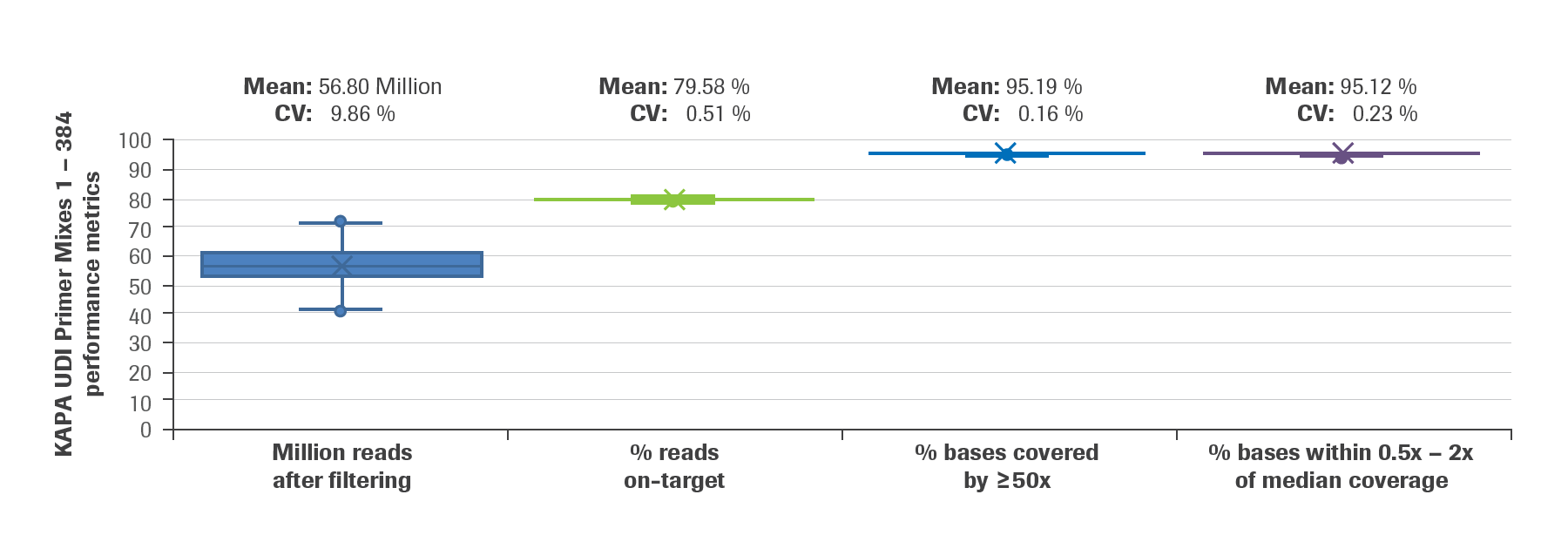
Figure 1. KAPA Universal Adapter with all 384 KAPA UDI Primer Mixes perform consistently in the KAPA HyperCap Workflow v3.
High reproducibility was demonstrated across all UDI pairs following the sequencing of duplicate libraries containing all 384 UDI pairs in a single run. Filtered reads delivered high specificity (% reads on-target), deep target coverage (% bases covered by > 50X), and high uniformity (% bases within 0.5X – 2X of median coverage). Total duplicate rate was 3.2 % + 0.2 % and fold-80 base penalty was 1.32 + 0.01. Experimental design: Duplicate libraries were prepared with the KAPA HyperCap Workflow v3 using the KAPA HyperCap Heredity Panel (10 Mb capture target) and the KAPA HyperPlus Kit; input = 100 ng of human genomic DNA (NA12878; Coriell Institute). Libraries were multiplexed prior to capture, a total of 12 x 32-plex captures (384 enriched libraries total). All enriched libraries were then pooled and sequenced on a NovaSeq™ 6000 System lane at 2 x 100 bp, resulting in a mean of ~56.8 Million reads per sample after quality filtering. After down-sampling at 20 Million reads per sample, analysis followed the technical note “How To Evaluate KAPA Target Enrichment Data” (March 2020)1. Total duplicate rate was 3.2 % + 0.2 % and fold-80 base penalty was 1.32 + 0.01.
1. Meyer, J, et al. Roche Application Note SEQ100183. 2018.
Somatic oncology research using cell-free DNA (cfDNA)
Accurate molecule counting is essential for somatic oncology applications, especially from low inputs of cfDNA where every molecule counts. This accuracy is enhanced by the use of Unique Molecular Identifiers (UMIs) incorporated into NGS adapters, providing barcodes for individual molecules.
- Prevent errors in the identification of UMIs with the proprietary design of KAPA Universal UMI Adapters
- Increase accuracy of molecule counting and achieve higher duplex recovery and lower error rates with KAPA UMI Adapters (compared to UMI adapters from another supplier)
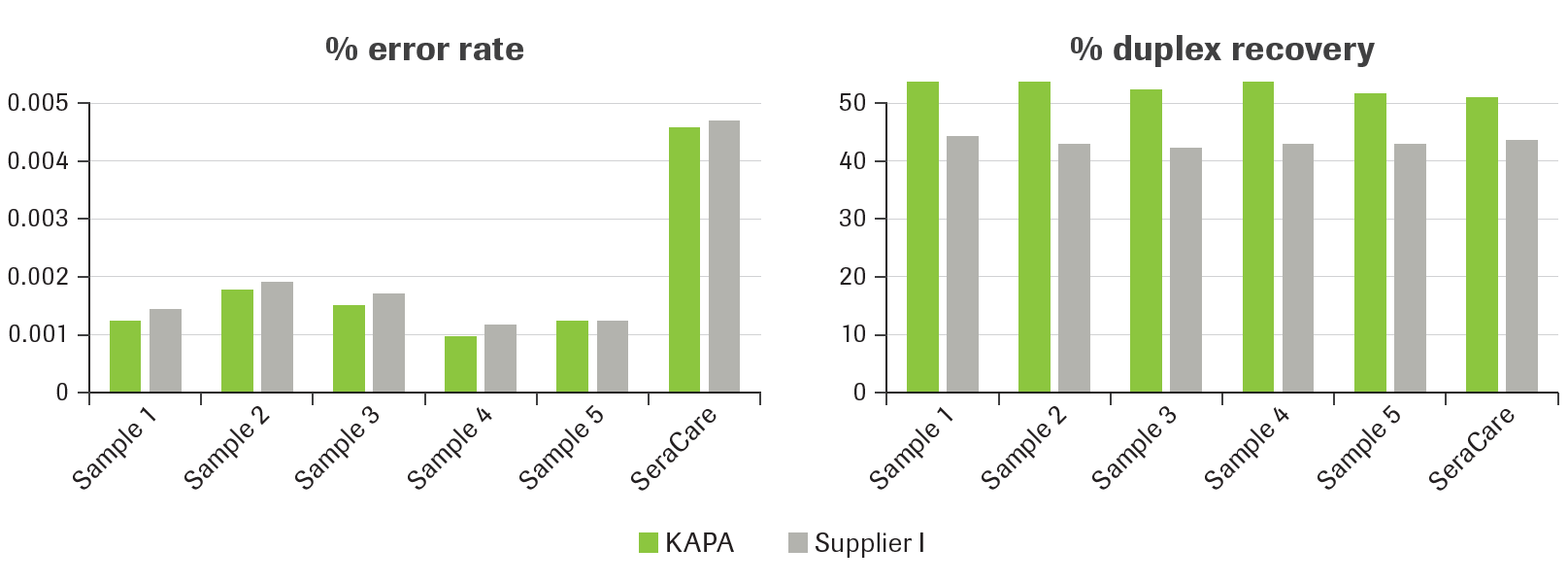
Figure 2. KAPA UMI Adapter supports highly accurate molecule counting and high recovery of duplex molecules from 10 ng cfDNA.
Five healthy donors’ cell-free DNA samples and the SeraSeq® ctDNA Complete™ Reference Material AF0.5% from SeraCare were tested in duplicate for library preparation and target enrichment with the KAPA HyperCap Oncology Panel (214 Kb capture target). Libraries from 10 ng cfDNA were prepared with the KAPA HyperPrep Kit and captured according to the KAPA HyperCap Workflow v1 for cfDNA in single hybridizations per sample. Sequencing clusters of 2 x 150 bp from a NextSeq™ 500 System were downsampled to 50 Million quality filtered clusters per sample prior to analysis.
Save valuable time and resources
KAPA Adapters are a collection of high quality, unique dual-indexed adapters for ligation-based library construction. KAPA Adapters support many levels of sequencing multiplexing (2-plex up to 384-plex) on both two- and four-channel Illumina instruments that use either patterned or non-patterned flow cells.
- Mitigate the impact of index misassignment with full-length KAPA Unique Dual-Indexed (UDI) Adapters, offering 96 adapters containing non-redundant index combinations, or with KAPA Universal Adapters plus KAPA UDI primer mixes
- Create up to 384 uniquely-indexed libraries with truncated KAPA Universal Adapters (with or without UMIs) and KAPA UDI Primer Mixes
KAPA Adapters Selection Guide*
View full tableKAPA Adapters Selection Guide*
|
KAPA UDI Adapters |
KAPA Universal Adapter |
|
|---|---|---|---|
|
KAPA Universal Adapter |
KAPA Universal UMI Adapter |
|
Number of UDIs (unique dual-indexes) |
96 | 384 |
|
Number of 8-nt non-redundant P5 + P7 barcodes |
96 + 96 | 384 + 384 | |
Barcodes identical to those used in adapters supplied by Illumina |
No(1) | No(1) | |
Recommended for all Illumina instruments with patterned or non-patterned flow cells |
Yes | Yes | |
PCR-free library preparation |
Yes | No | |
Molecular barcoded |
No | No | No |
| Suitable for: KAPA HyperPrep & HyperPlus KAPA EvoPlus KAPA RNA HyperPrep KAPA HyperCap |
Compatible Validated Compatible(2) |
Compatible Compatible Validated Validated |
Compatible
Compatible Validated |
Compatible with KAPA Universal Enhancing Oligos |
Yes | Yes | |
Adapter formulation |
Full-length, ready-to-use, 15 μM |
Truncated, ready-to-use, 15 μM |
Truncated, ready-to-use, 33 μM |
Kit configuration |
Hard-shell 96-well plate with automation-friendly labelling, overage and replacement seals(4) |
Adapter tube and hard-shell 96-well primer mixes plates with automation-friendly labeling, overage and replacement seals(4) |
|
KAPA Adapter Dilution Buffer |
Yes (25 mL per kit) |
No | |
(1)The sets of 192 and 768 barcode sequences used in KAPA UDI Adapters and KAPA UDI Primer Mixes (respectively) are exclusive to Roche and different between the two sets.
(2) Theoretically possible but not fully tested.
(3) This is sufficient for four or one library preps (KAPA UDI Adapter plate or KAPA UDI Primer Mixes plate, respectively) with the KAPA HyperPrep or KAPA HyperPlus Kit if no adapter dilution is required. Generous overfill supports use on automated liquid handling systems.
(4)KAPA UDI Primer Mixes and KAPA Adapter plates are shipped with peelable seals. Replacement seals (three per plate) are peelable and pierceable.
* KAPA Universal Adapters, KAPA Universal UMI Adapters and KAPA UDI Adapters are not compatible with methyl-seq applications.
For purchasing or general questions
For online ordering
| KAPA Code |
Roche Cat. No |
Description |
Kit Size |
How to buy |
|---|---|---|---|---|
| KK8721 |
08278539001 |
KAPA Adapter Dilution Buffer (25 mL) | 25 mL |
Login for pricing |
| KK8727 |
08861919702 |
KAPA Unique Dual-Indexed Adapter Kit, (15 µM) |
96 adapters x 20 µl each |
Login for pricing |
| KAPA Code |
Roche Cat. No |
Description |
Kit Size |
How to buy |
|---|---|---|---|---|
| 09134336001 |
09134336001 |
KAPA UDI Primer Mix, 1-96 | 96 rxn |
Login for pricing |
| 09063781001 |
09063781001 |
KAPA Universal Adapter, 15 µM | 960 µL |
Login for pricing |
| 09063790001 |
09063790001 |
KAPA Universal Adapter, 15 µM | 4 x 960 µL |
Login for pricing |
| 09329862001 |
09329862001 |
KAPA Universal UMI Adapter, 33 µM |
960 µl |
Login for pricing |
| 09329846001 |
09329846001 |
KAPA UDI Primer Mix, 193-288 |
96 rxn |
Login for pricing |
| 09329854001 |
09329854001 |
KAPA UDI Primer Mix, 289-384 |
96 rxn |
Login for pricing |
| 09329838001 |
09329838001 |
KAPA UDI Primer Mix, 97-192 |
96 rxn |
Login for pricing |
For purchasing or general questions
For online ordering