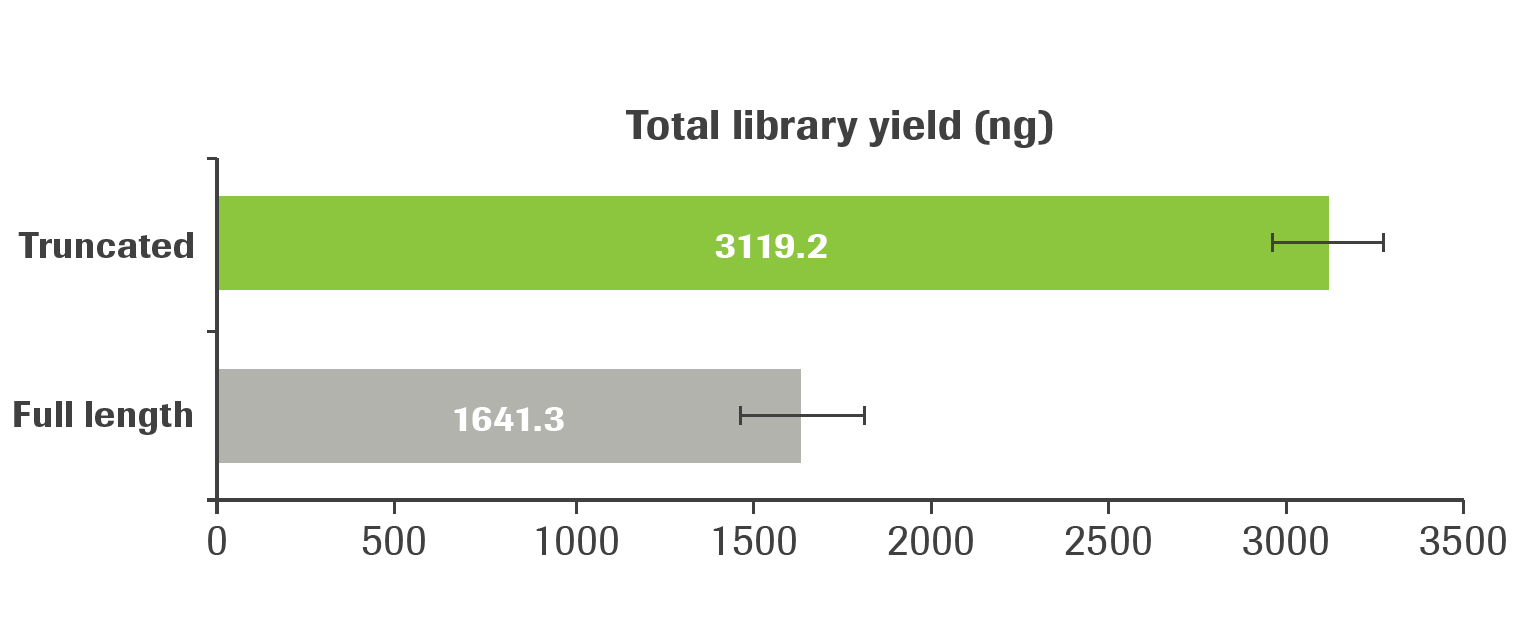
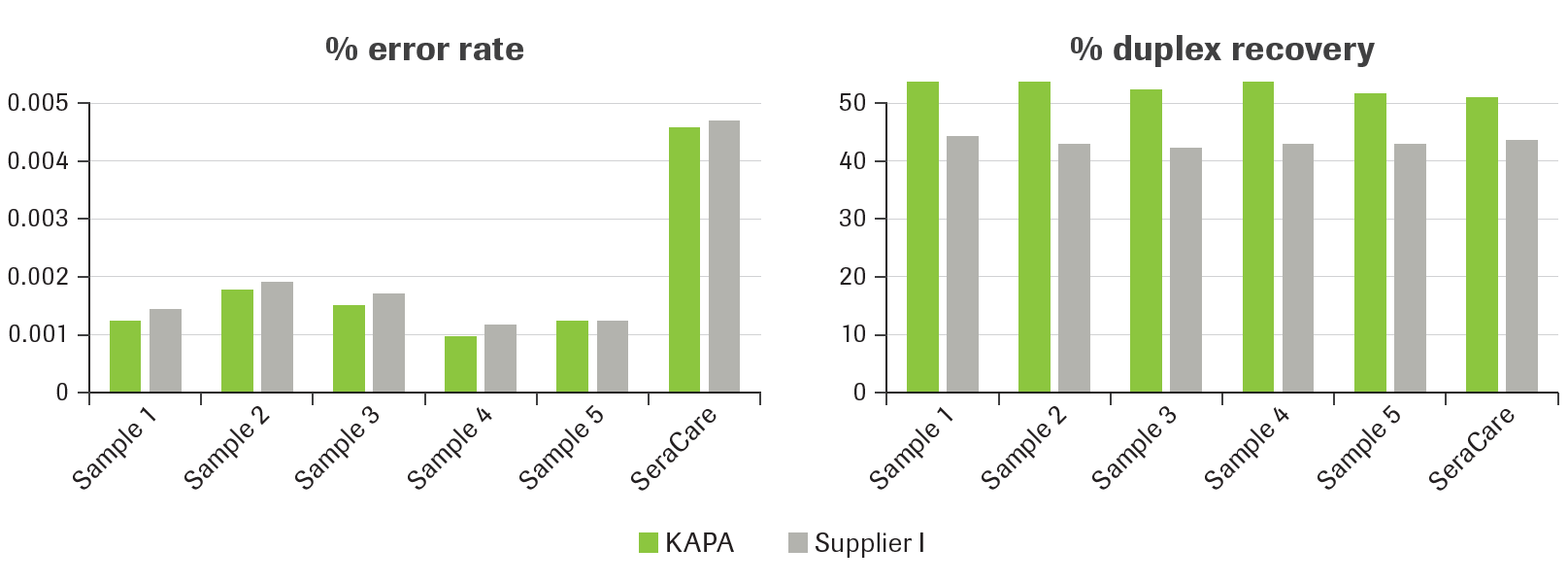
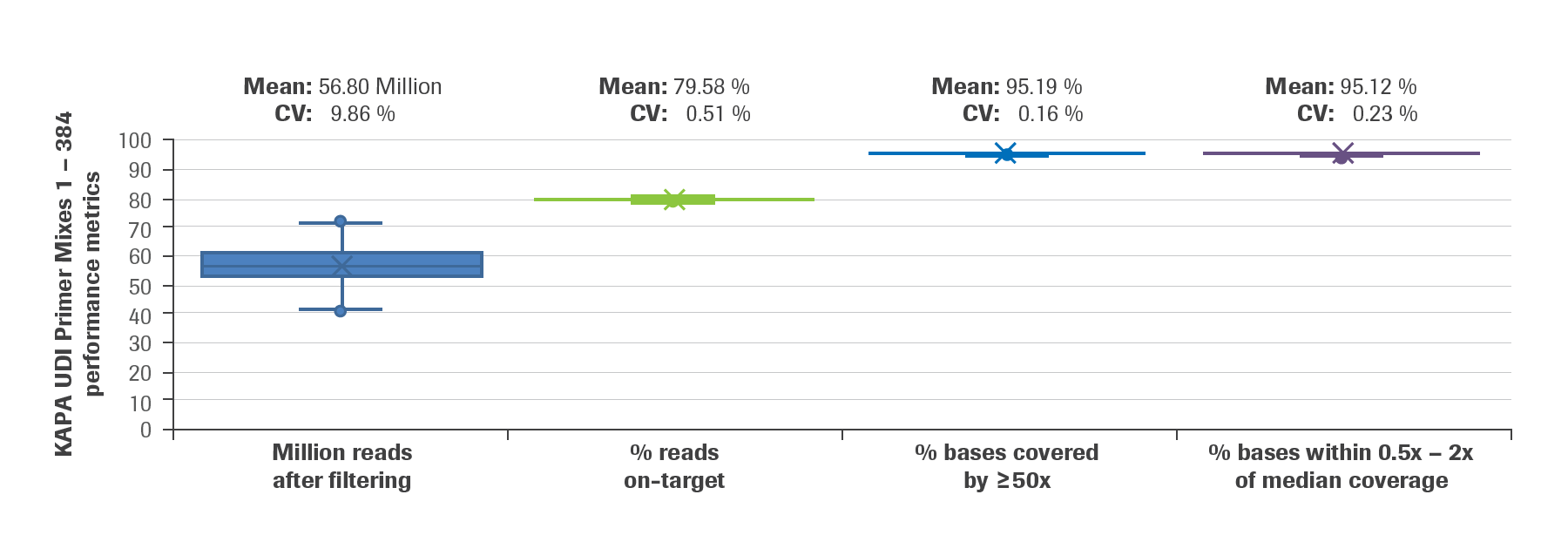
Truncated adapters are compatible with ligation-based library construction research workflows for direct and targeted multiplexed DNA and RNA (cDNA) sequencing applications on the Illumina® platform. Sequencing barcodes are added with UDI primer mixes during the library amplification step.
KAPA HyperPlex Adapters have a standard Illumina adapter backbone. They are therefore easily incorporated in new and existing Illumina sequencing workflows, and do not require customized sequencing primers. A combination of 8-nt sequencing barcodes on each of the i5 and i7 adapter oligos supports paired-end sequencing on 1- , 2- and 4-channel Illumina instruments. KAPA HyperPlex Adapters support a broad range of sample pooling (2- plex up to 384-plex, as appropriate for your workflow), for target enrichment and/or sequencing research.
Unique dual-indexing is recommended for all applications and Illumina sequencers.1,2